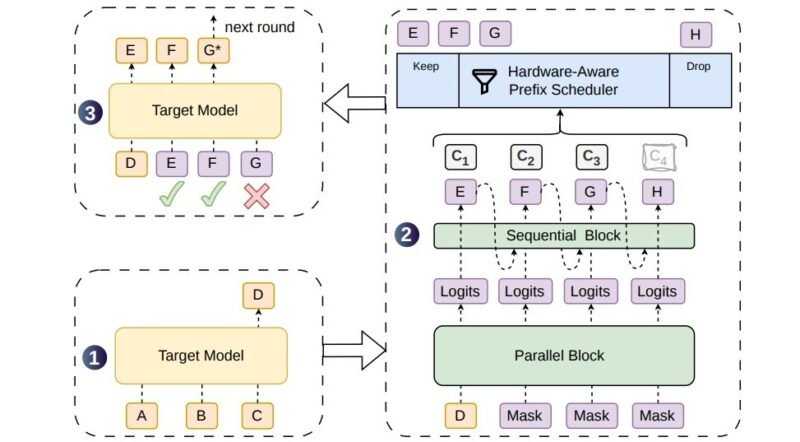

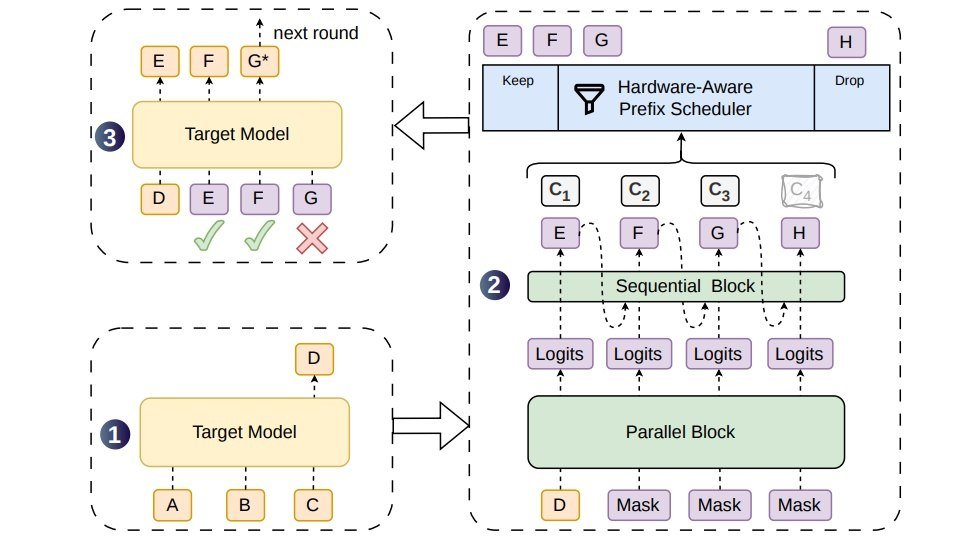
大模型生成文本时逐 token 串行计算,推理延迟随输出长度线性增长,这是 AI 对话偏慢的核心原因。6 月 27 日,DeepSeek 联合北京大学发布 DSpark 推理加速框架,通过半自回归候选生成与置信度调度验证两项机制,在同等吞吐量下将单用户生成速度提升 60% 至 85%。
DSpark 的并行主干一次性产出全部候选 token 的隐藏状态,再由轻量顺序模块逐 token 注入前缀依赖,兼顾了并行效率与候选接受率;调度器则根据置信度动态决定验证长度,优先把算力分配给高存活概率的 token。该框架已部署于 DeepSeek-V4-Flash 与 V4-Pro 预览版,不同 SLA 条件下生产环境吞吐量提升显著,目前相关代码与模型已在 GitHub 和 Hugging Face 开源。
Deepseek | Hugging Face | IT之家
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容