
英伟达刷新 DeepSeek V4 推理纪录:单 Token 成本降至五分之一
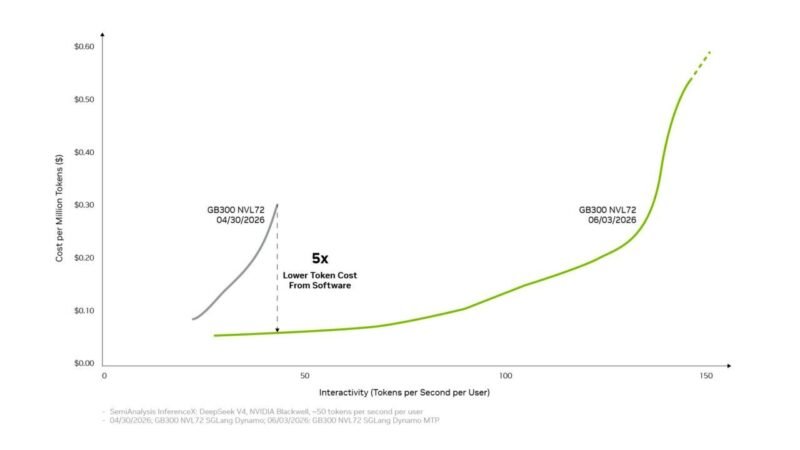
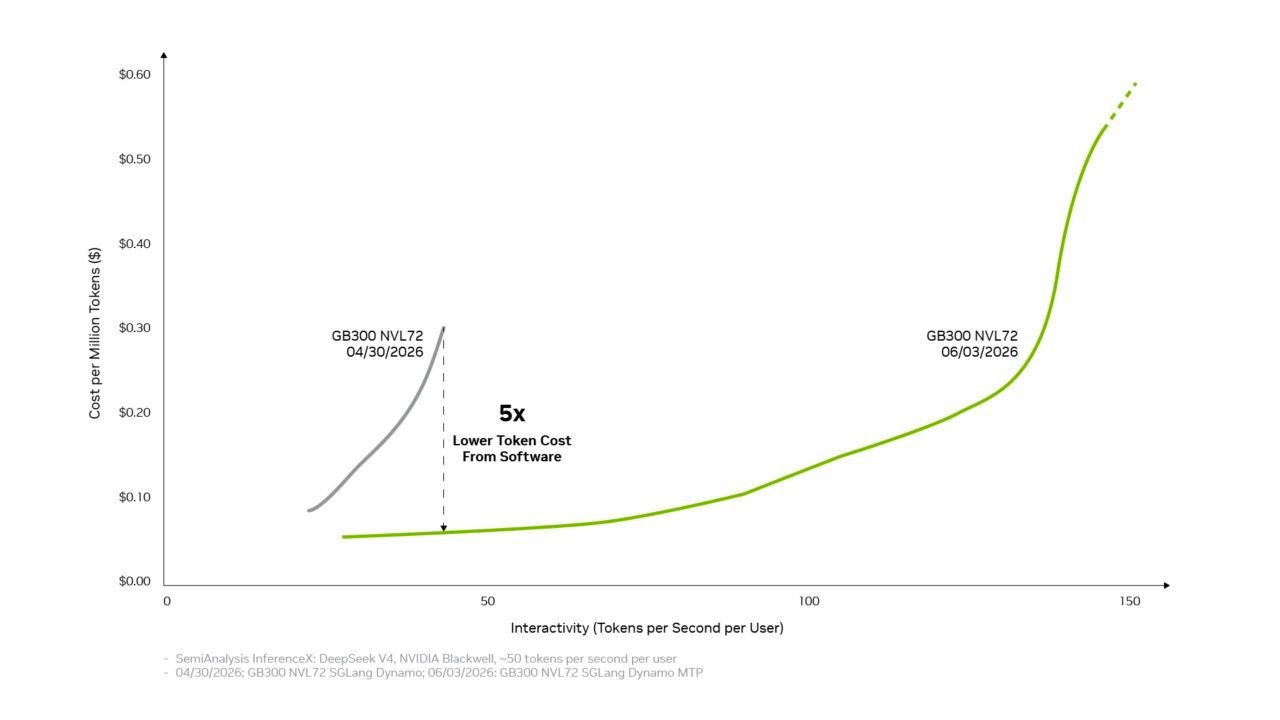
NVIDIA 推理软件栈在 Blackwell 平台上持续优化,使得 DeepSeek V4 模型的 Token 生成成本在一个月内降至原先的五分之一。来自 PyTorch 社区的数据显示,在 GB300 离散式部署下,SGLang 引擎的吞吐量从 4 月初的约 2,200 Tokens/秒/GPU,提升至 6 月的约 11,200 Tokens/秒/GPU。这意味着在保持用户约 50 Tokens/秒的高流畅交互体验不变的同时,性能实现了 5 倍的增长。此外,Blackwell Ultra 的聚合部署方案也获得了近 3 倍的提升。
这一性能飞跃得益于多项内核与运行时的深度优化,包括融合技术、显存压缩、量化精度路径,以及改进后的内存预算、可中断计算图支持与推理稳定性修复。NVIDIA 方面表示,若后续再叠加分解式服务、新浮点精度与多 Token 预测等高级优化,系统级吞吐量最高有望提升至 20 倍。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容