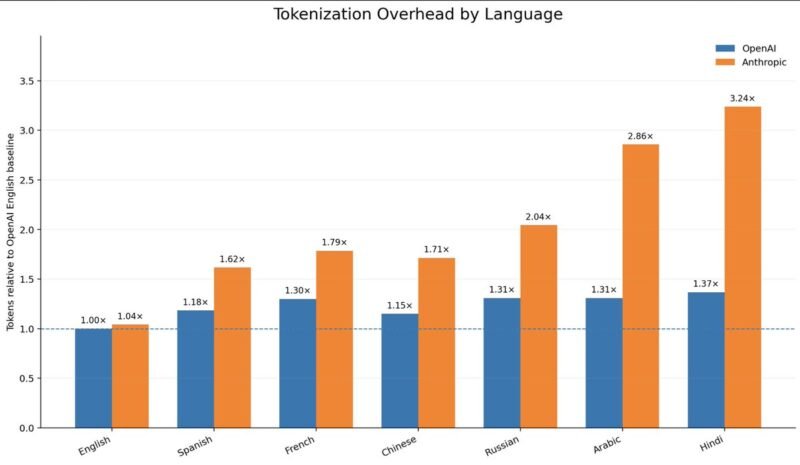

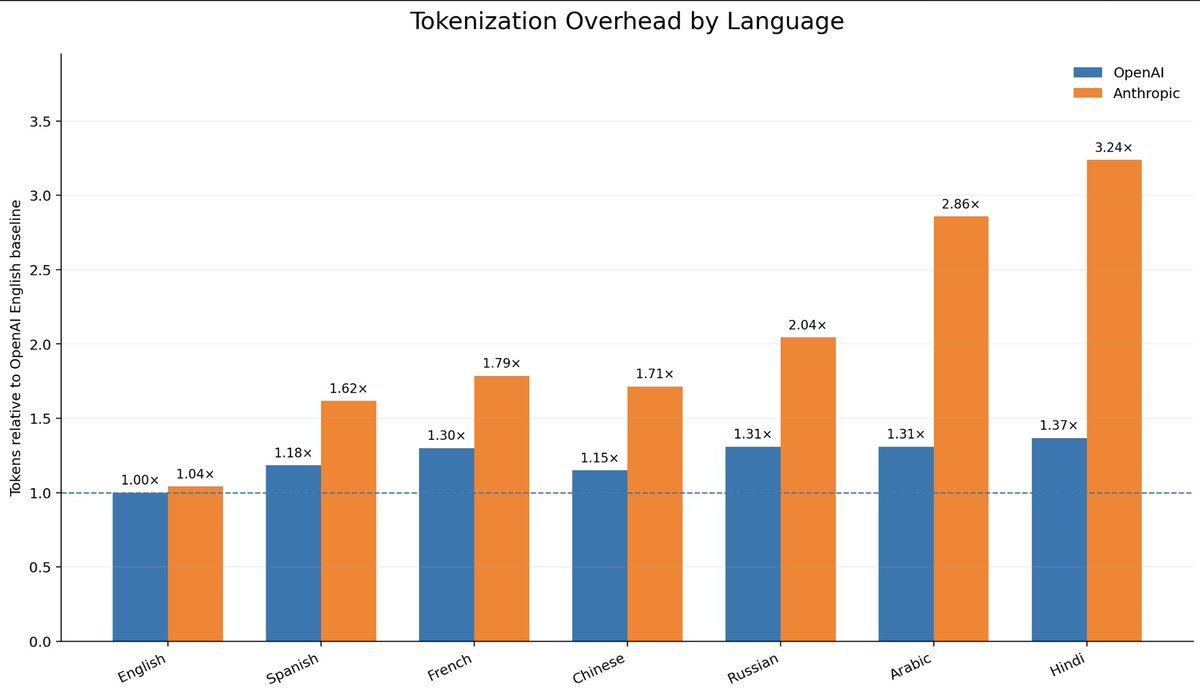
非英语语言 token 成本:Anthropic 使用中文消耗高出 71% ,中国模型对中文更友好
研究人员对比发现,不同模型的 tokenizer 对非英语文本处理效率差异明显。以《苦涩的教训》一文翻译文本为例,中文在 Anthropic 模型上的 token 消耗是 OpenAI 的 1.71 倍,印地语高达 3.24 倍,阿拉伯语为 2.86 倍。
后续测试更多模型-语言对表明,Gemini 和 Qwen 的非英语额外开销最小,Anthropic 最高,Kimi 次之。中国主流模型处理中文时,甚至比处理英语更节约 token。印地语尽管使用人数众多,但在此对比中 token 效率最低。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END










暂无评论内容